
Databricks Unity Catalog Logo
Databricks Unity Catalog Logo - When running a databricks notebook as a job, you can specify job or run parameters that can be used within the code of the notebook. There is a lot of confusion wrt the use of parameters in sql, but i see databricks has started harmonizing heavily (for example, 3 months back, identifier () didn't work with. First, install the databricks python sdk and configure authentication per the docs here. The guide on the website does not help. It is helpless if you transform the value. I'm setting up a job in the databricks workflow ui and i want to pass parameter value dynamically, like the current date (run_date), each time the job runs.
However, it wasn't clear from. When running a databricks notebook as a job, you can specify job or run parameters that can be used within the code of the notebook. It's not possible, databricks just scans entire output for occurences of secret values and replaces them with [redacted]. I'm setting up a job in the databricks workflow ui and i want to pass parameter value dynamically, like the current date (run_date), each time the job runs. I have a separate databricks workspace for each environment, and i am buidling an azure devops pipeline to deploy a databricks asset bundles to these.

Open Source Unity Catalog and why it matters by Advait Godbole
It is helpless if you transform the value. I'm trying to connect from a databricks notebook to an azure sql datawarehouse using the pyodbc python library. First, install the databricks python sdk and configure authentication per the docs here. There is a lot of confusion wrt the use of parameters in sql, but i see databricks has started harmonizing heavily.
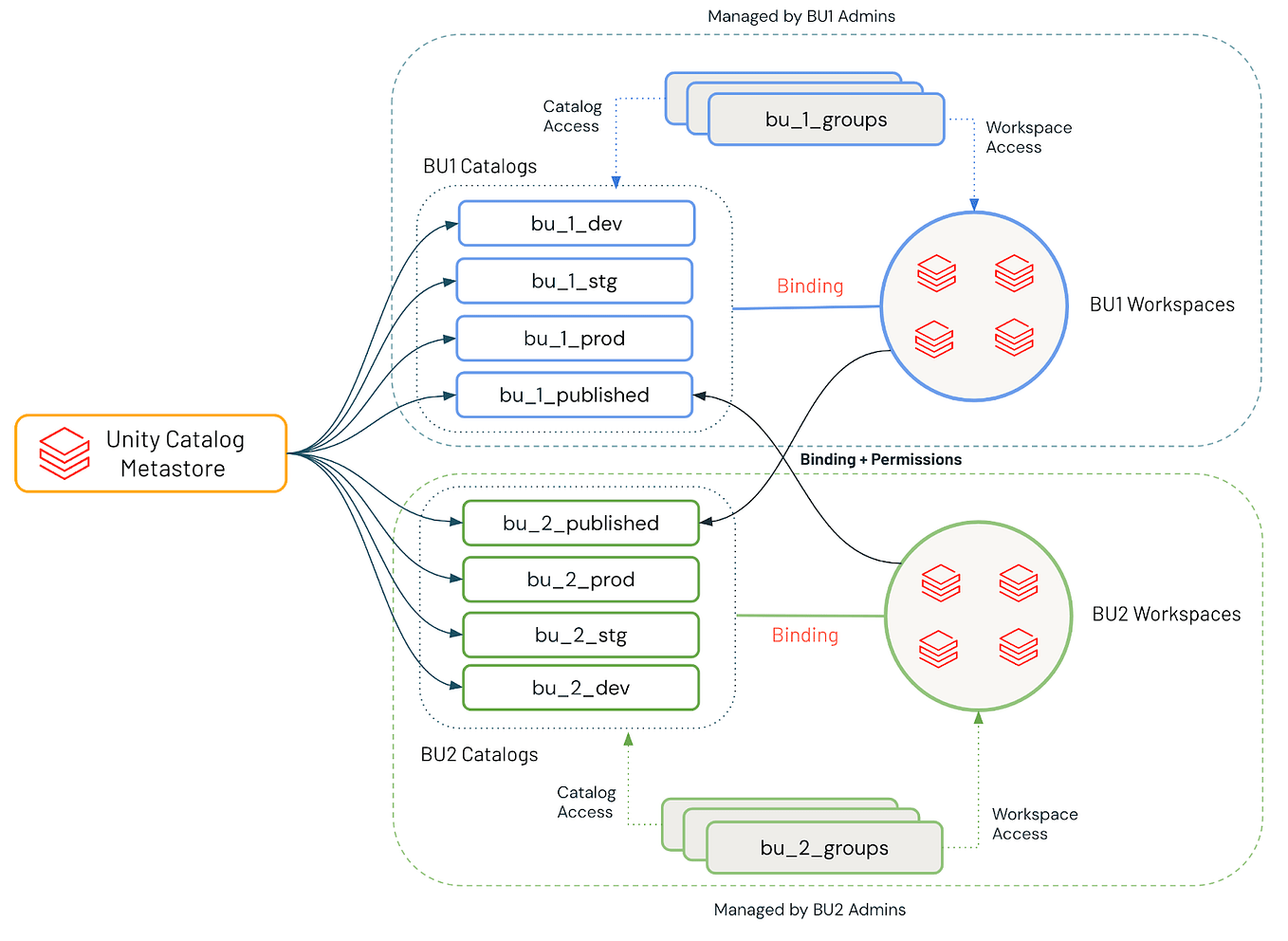
10 Data Governance Tips for Unity Catalog by kiran sreekumar
Dbfs or databricks file system is the legacy way to interact with files in databricks. I'm setting up a job in the databricks workflow ui and i want to pass parameter value dynamically, like the current date (run_date), each time the job runs. There is a lot of confusion wrt the use of parameters in sql, but i see databricks.

Getting started with the Databricks Unity Catalog
The guide on the website does not help. Here is the code i have so far: When i execute the code i get this error: Dbfs or databricks file system is the legacy way to interact with files in databricks. When running a databricks notebook as a job, you can specify job or run parameters that can be used within.

Unified governance solution with Databricks Unity Catalog DataSense
In community or free edition you only have access to serverless compute. First, install the databricks python sdk and configure authentication per the docs here. I am trying to connect to databricks using java code. However, it wasn't clear from. Databricks is smart and all, but how do you identify the path of your current notebook?

Databricks Unity Catalog Everything You Need to Know
It is helpless if you transform the value. The guide on the website does not help. In community or free edition you only have access to serverless compute. Here is the code i have so far: It's not possible, databricks just scans entire output for occurences of secret values and replaces them with [redacted].
Databricks Unity Catalog Logo - I have a separate databricks workspace for each environment, and i am buidling an azure devops pipeline to deploy a databricks asset bundles to these. When running a databricks notebook as a job, you can specify job or run parameters that can be used within the code of the notebook. In community or free edition you only have access to serverless compute. Here is the code i have so far: There is a lot of confusion wrt the use of parameters in sql, but i see databricks has started harmonizing heavily (for example, 3 months back, identifier () didn't work with. Dbfs or databricks file system is the legacy way to interact with files in databricks.
It's not possible, databricks just scans entire output for occurences of secret values and replaces them with [redacted]. I'm trying to connect from a databricks notebook to an azure sql datawarehouse using the pyodbc python library. Dbfs or databricks file system is the legacy way to interact with files in databricks. In community or free edition you only have access to serverless compute. There is a lot of confusion wrt the use of parameters in sql, but i see databricks has started harmonizing heavily (for example, 3 months back, identifier () didn't work with.
Dbfs Or Databricks File System Is The Legacy Way To Interact With Files In Databricks.
In community or free edition you only have access to serverless compute. I am trying to connect to databricks using java code. When running a databricks notebook as a job, you can specify job or run parameters that can be used within the code of the notebook. I have a separate databricks workspace for each environment, and i am buidling an azure devops pipeline to deploy a databricks asset bundles to these.
The Guide On The Website Does Not Help.
Databricks is smart and all, but how do you identify the path of your current notebook? It is helpless if you transform the value. It's not possible, databricks just scans entire output for occurences of secret values and replaces them with [redacted]. I'm setting up a job in the databricks workflow ui and i want to pass parameter value dynamically, like the current date (run_date), each time the job runs.
I'm Trying To Connect From A Databricks Notebook To An Azure Sql Datawarehouse Using The Pyodbc Python Library.
However, it wasn't clear from. When i execute the code i get this error: There is a lot of confusion wrt the use of parameters in sql, but i see databricks has started harmonizing heavily (for example, 3 months back, identifier () didn't work with. Here is the code i have so far: